
We talked about transformers a few times here and there in other deep dives or feature articles. However, they represent such a pivotal innovation in the world of Natural Language Processing and Deep Learning, that they deserve an in-depth explanation. In this first part of our series, Transformers explained, we are going to see at transformer at a high level, and try to understand why they are so popular. So go ahead, get comfortable, and let’s dive in!
Transformers – Explaining Why
Before Transformers
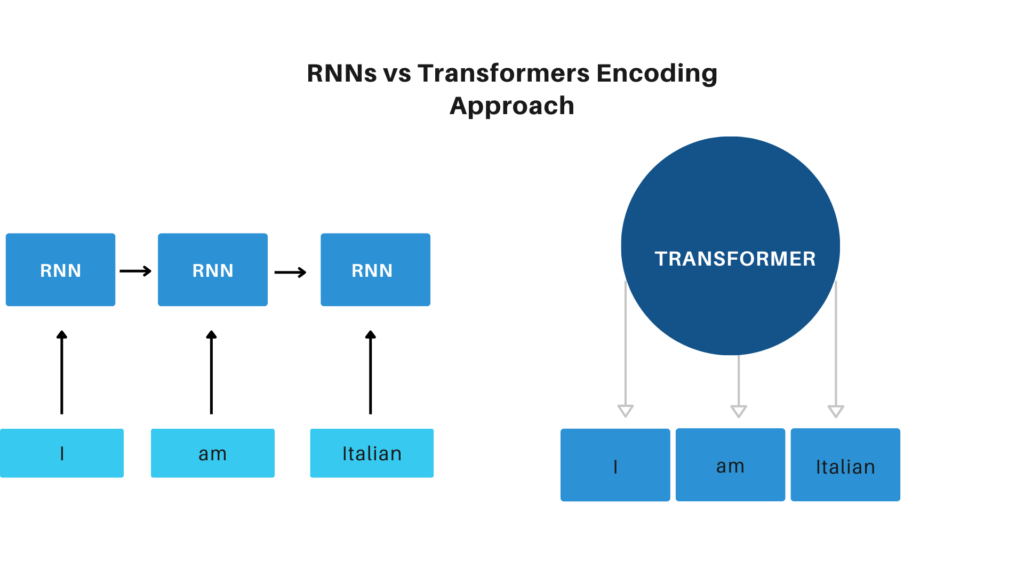
Before Transformers entered the scene, RNNs in all their flavors, such as LSTMs and GRUs, were the standard architecture for all NLP applications.
RNNs have Their Own Problems
These architectures presented two main issues:
- Longer sentences were hard to encode without losing meaning. Because of the nature of the RNN, encoding dependencies between words that were far apart in the sentence was challenging. This is due to the vanishing gradient problem.
- The model processes the input sequence one word at a time. This means that until all the computation for time step t1 is not finished, we cannot start computing for time step t2. In other words, the computation is time-consuming, which is problematic for both training and inference.
Transformers Explained – Why
Explaining Transformers to my Mum
Ok, so now we have seen why transformers are so popular. It is now time to look at how they work. However, transformers are complex yet elegantly simple models, and it’s hard to do them justice in a few words without forgetting any detail. So for the moment, I’ll explain transformers at a very high level, pretty much as I would explain them to my mum. So here we go.
For the moment, let’s just imagine transformers as a big box. This big box takes in a some information, like a phrase or a picture, and gives you back something in return, depending on what type of box you have. Some of these boxes take a picture and give you back a description of said picture; others take a paragraph and give you back a summary. Some answer questions, and some paraphrase sentence. Others yet even take a phrase and give you back a picture.
Now, this is not a magic box. There is a really simple yet powerful mechanism behind all this: the Attention mechanism. This mechanism allows the Transformer to take in all the information at once (all the words in a sentence, or all the pixels in a picture, for example), and decide which are the most important one, to correctly decode the information. Exactly how humans do when they are talking, translating, studying, etc!
In the next episode of this saga, we are going to learn how Attention is used in a Transformer. We are going to get technical, but don’t worry, it’s going to be fun!


