HuggingFace’s BigScience Model Training Launched
On March 11, 2022, the HuggingFace team announced that training on the BigScience Large Language Model had started. If you are not familiar with the project, HuggingFace launched the initiative a year ago. The project reunites more than a thousand researchers from all over the world, and culminated in the final design of a 176 billion parameter transformer model. The model will be trained on more than 300 billion words in 46 different languages.
This is great news. The BigScience project is a unique open science initiative, that allows lambda users to follow along the training every step of the way. So let’s look at the project features and training more in detail to better understand what this means for the Deep Learning industry.
Size and Specs and How it all Came Together
As mentioned, BigScience is a transformer that will have 176 billion parameters. While training, it will go over roughly 250 billion words. Data has been responsibly curated, and we will have a look at the making of the dataset in this article. The size was chosen based on the resource availability.
The project is in collaboration with the French National Center for Scientific Research (CNRS), that made available Jean Zay, the French Government-funded super computer managed by GENCI. Researchers have 18 weeks of computer on the cluster. 18 weeks on 384 A100 80 GB GPUs means 1,161,261 hours of training. If you want to learn more about the hardware used for the project, I suggest this very informative article from the BigScience blog. The issue of carbon emissions while training Large Language Models (LLMs), an issue I talked about in this article, is also tackled in the article.
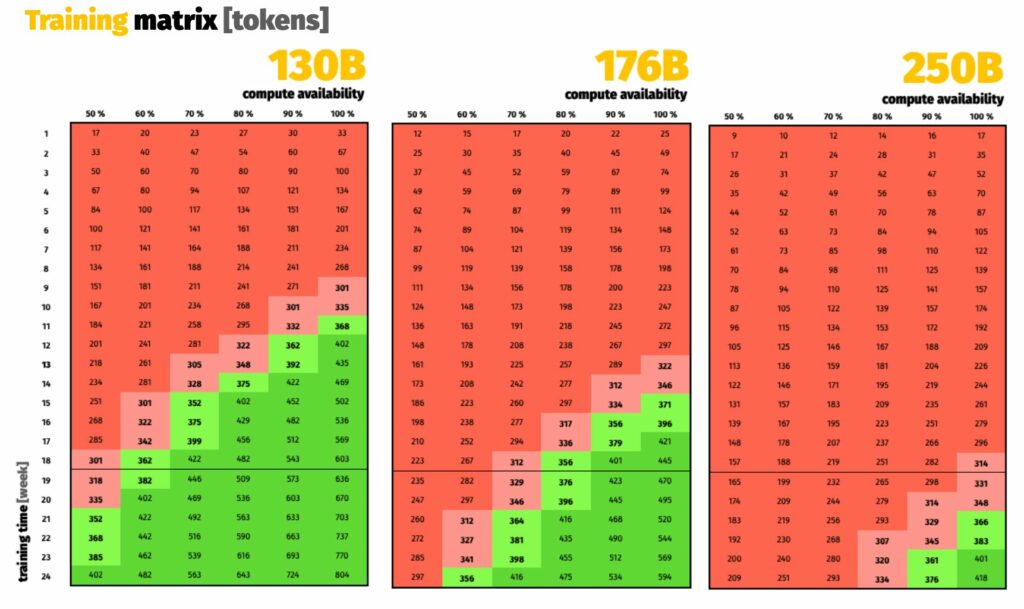
Researchers developed scaling laws that gave them an upper constraint on the “best” possible model: 392B parameters trained for 165B tokens. However, serving/inference costs, downstream task performance, and other factors are not taken into consideration by these scaling rules. Furthermore, researchers wanted to ensure that low-resource languages received sufficient tokens during pretraining. This way, the model wouldn’t be forced to zero-shot whole languages. As a result, they decided to at least pretrain for 300-400B tokens.
Given the available GPU time, researchers estimated how many tokens they could use to train different sized models, accounting for safety margins. A 175 billion parameter model allowed them to comfortably train more than 300 billion tokens, perhaps even 400 billions (see Figure 1).
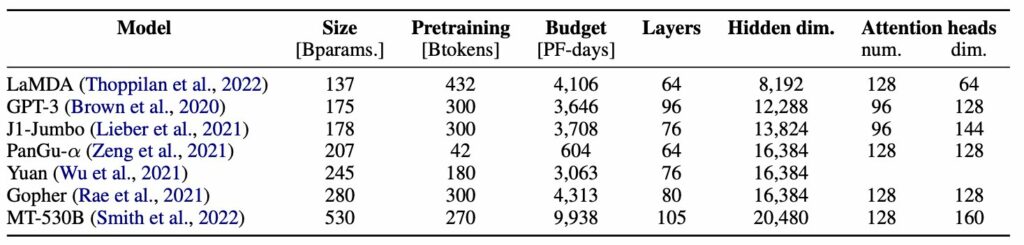
Engineers then went on to decide the shape of the model based on other LLMs and previous pieces of research, such as Kaplan et al. (2020), and Livine et al. (2020).
Finally, hundreds of possible configurations were benchmarked to find the fasted one. Stas Berkman, one of BigScience’s engineers, chronicles the process and the training. You can See the configs in Figure 2. The winning one is in bold.
What Makes HuggingFace’s BigScience special?
A project of this size is obviously a feat per se. But what makes BigScience truly stand out in a world of Large Language Models (LLMs) is its openness. Like the Large Hadron Collider or the Hubble Telescope, that have led to incredible breakthroughs in their respective fields, BigScience is an open science project. Everything about the project is as open and as transparent as possible, and researchers have come together to strive for the best possible results. The code is open source, and research findings are shared. A final presentation will be held at the ACL conference in May.
The results of the project, come from the group effort o more than a thousand researchers from 30 different work groups. The model is a feat in collaboration in the field.
Keeping in mind the openness and collaboration that make this project unique, the final aim of the project would be to make the model accessible to anyone via an API. This would make the model available even to those who do not have the computing power to run the model themselves. The final licensing of the model is being drafted at the moment.
Even the dataset was constructed with an inclusive approach in mind, and data governance was an important point for the work group. All the data sources used to train the model will be available to researchers, that will even be able to reuse a significant portion of the dataset for future projects.
So what does this mean?
Regardless of the results of the project (which has all the basis to produce a powerful language model), this open science project ushers in a new era in NLP. Up until now, the inner workings of configuring and training a Large Language Model, with all that the process entails (deciding the number of parameters and training tokens, benchmarking the different shapes, as well as curating the data to create the dataset) were reserved for the VIPs.
Large (usually private) organizations that kept at least some of their secrets close to the heart. They would typically make their training and configurations upstream, thanks to the vast amount of computational resources they have available, while the rest of us remained downstream. We can use pre-trained models, fine-tune them, make amazing things even, but, we are not truly part of the process.
With BigScience the entire project becomes open science. Everything will be shared. This is incredibly important, since we will now partake in valuable information, and we could even be able to contribute to the discussion. The move is not surprising on the part of HuggingFace, which has always been an advocate for open and shared resources, especially when sharing also means cutting down on the environmental impact of Deep Learning.
Given the potential impact of language model technology, it is important that the broader community has a good understanding of how they are constructed, how they function and how they can be further improved. Up until now, much of this knowledge has been restricted to a handful of people in elite resource-rich research groups and corporations, who have—for financial, legal or ethical reasons—not been very open about the scientific details and even if they did publish scientific papers, did not open source the actual research artifacts.
And there you have it! A quick overview of HuggingFace’s BigScience Language model. I will shortly write another article to talk about how the dataset was built. In the meantime, you can have a look at these other sources to keep up with the project:
- BigScience Research Workshop Twitter
- BigScience Large Model Training Twitter
- Stas Berkman’s chronicles
- What Language Model to Train if You Have One Million GPU Hours?
- BigScience model training launched
- What Language Model to Train if You Have One Million GPU hours? (blog post
- BigScience’s Tensorboard
- BigScience Workshop Website
- Which hardware do you need to train a 176B parameters model?


